STT Translate & Transcribe! 
Gradio_GenerativeAI Tool To Transcribe & Translate Audio

About 📝
> Using OpenAI Whisper Base model to transcribe audio files into text Google Madlad model to translate transcribed texts into multiple languages.
> Enabling users to convert spoken words into written text.
> Supporting various use cases, including transcription of audio files, detection of phrases, speech-to-text generation, and translation of text.
How it Works 🫶
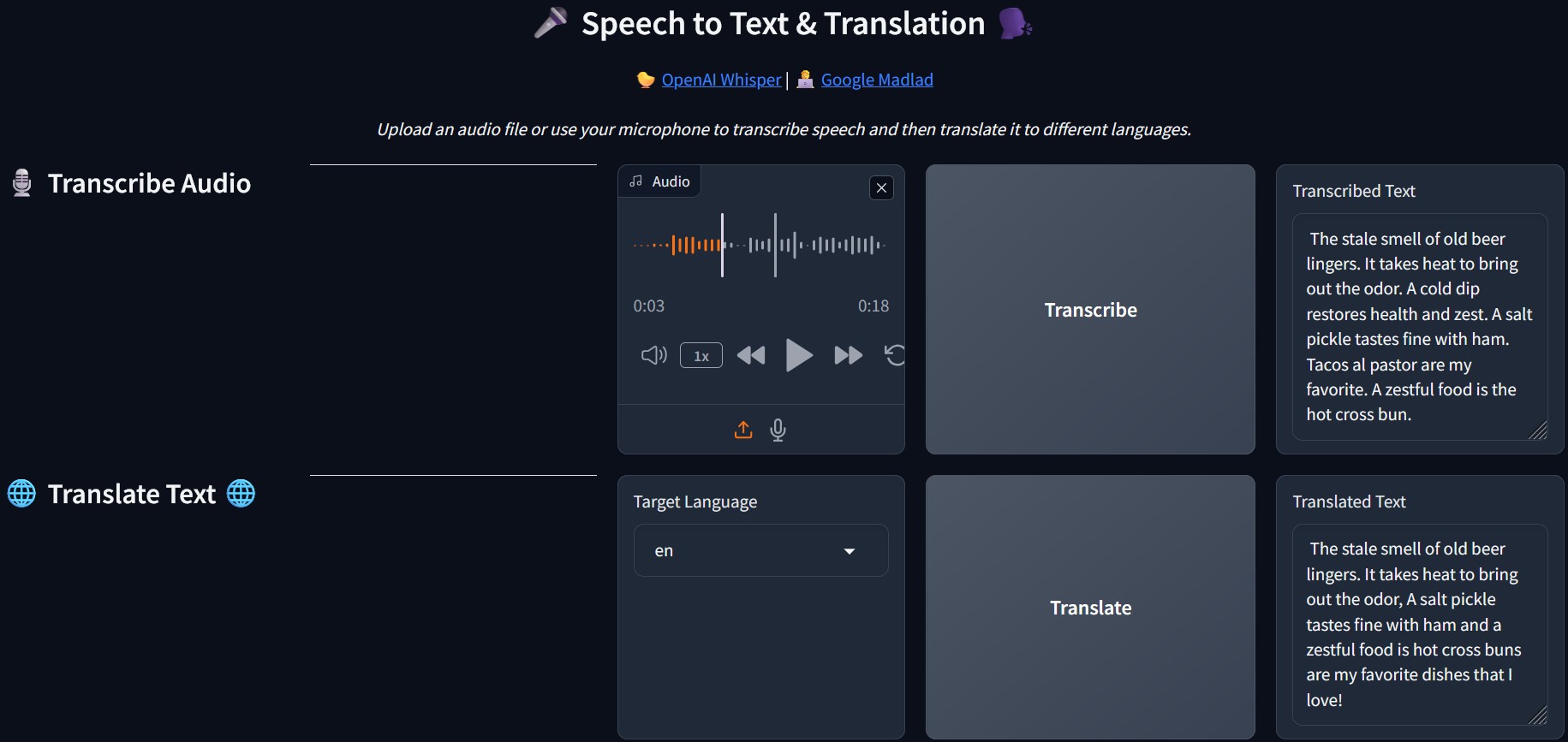
- Upload an audio file or record a new one directly in the app.
- Transcribe the audio into text, allow copy and paste function for further use.
- Or/ Translates the transcribed text into multiple languages (400+ languages)
Usage 🤗
- Transcribe audio files for note-taking, research, or content creation
- Detect phrases or keywords in audio recordings for data analysis or market research
- Generate text from speech for speech-to-text applications, such as subtitles, closed captions, or voice assistants
- Use the app for language learning, by transcribing audio files in a foreign language and practicing pronunciation
- Translate the transcribed text into multiple languages for global communication
Features 🎉
- Supports audio files and live recording 📻
- Uses the OpenAI Whisper Base model for speech recognition 💬
- Displays transcribed text in the app 📝
- Allows you to copy and paste the transcribed text for further use 📋
- Translates the transcribed text into multiple languages using the Google Madlad model 🌎
Model Details 📊
" "🐤 OpenAI Whisper | " "🧑💻 Google Madlad |" "
The OpenAI Whisper Base model is a pre-trained model for automatic speech recognition (ASR) and speech translation.
It was trained on 680k hours of labelled data and demonstrates a strong ability to generalize to many datasets and domains without fine-tuning.
| Size | Parameters | English-only | Multilingual |
|---|---|---|---|
| tiny | 39 M | ✓ | ✓ |
| base | 74 M | ✓ | ✓ |
| small | 244 M | ✓ | ✓ |
| medium | 769 M | ✓ | ✓ |
| large | 1550 M | x | ✓ |
| large-v2 | 1550 M | x | ✓ |
| large-v3 | 1550 M | x | ✓ |
For both the machine translation and language model, MADLAD-400 (Multilingual (400+ languages)) is used. For the machine translation model, a combination of parallel datasources covering 157 languages is also used. Using a Sentence Piece Model with 256k tokens shared on both the encoder and decoder side. Each input sentence has a <2xx> token prepended to the source sentence to indicate the target language.



See the research paper for further details.
🙅♂️Disclaimer
This app is licensed under AGPL-3.0 License and is for personal use only and should not be used for commercial purposes. The OpenAI Whisper Base model and Google Madlad model are pre-trained models and may not always produce accurate results.
Get Involved! 😌
I hope you found this project informative and engaging! 😊
If you’re interested in collaborating and contributing to the project, please let me know! I’d love to hear from you.
Getting Started 🚀
To get started with this project, you’ll need to:
- Clone the repository
- Install the required dependencies using
pip install -r requirements.txt📦 - Run the application using
python app.py🤖
Enjoy working with the content! 😊